[Paper Review] Controlling Linguistic Style Aspects in Neural Language Generation
A controllable text generator is useful in many areas. It refers to a text generative model which enables user to control various level of attributes. Despite the usefulness, there are very limited literatures studying the problem.
Published in 2017, this paper is one of the highly cited work in the field. It has shown a promising result on text generation with multiple attributes controlled at the same time. Not oly that, the work has also shown that it could generalize well even in combinations of attributes that are unseen in training set. It is a big deal because most data are skewed in a particular regions of attribute combinations, such finding means their work could probably generalize well on those kinds of data.
1. Problem Formulation
The paper formulate the problem as learning a conditional language model. A conditional language model learns a probability distribution for a sequence of words. More formally, a conditional language model is to learn $P(w_{1},…,w_{n} \mid c) = \prod^{n}_{t=1} P(w_{t} \mid w_{1},…,w_{t-1},c)$ , where $c$ is a vector of attributes where we want to control, and $w_i$ is the word at timestep $i$. In this work, they concatenate $c$ with the input vector in order to factor in the conditioning of attributes.
Compared with unconditional language model, where $P(w_{1},…,w_{n}) = \prod^{n}_{t=1} P(w_{t} \mid w_{1},…,w_{t-1})$ , the difference is that it has an additional attribute vector on its conditional term. In addition, collecting training data for conditional language model is usually more expensive than that for unconditional language model because one has to manually annotate the corresponding attributes for each text.
The authors demonstrate their work with LSTM model on a movie review dataset and claim that the framework is generally applicable to any recurrent models. In fact, with the latest NLP advancement, we see that such conditional language model is also applicable to feed-forward model such as BERT and GPT-2 as well (see this work for applying a similar framework on transformer model).
**In the paper, the authors refer attributes as “stylistic properties”. For naming consistency, I would also denote attributes as “stylistic properties” in the following sessions.
2. Dataset
The dataset they use is a huge corpus of movie reviews from Rotten Tomatoes website. The dataset contains meta-data for each raw text of movie review.
The paper spent a considerable length on how they clean the dataset. Oddly I find this session particularly insightful because handling messy data is a common issue in most manchine learning projects. The raw data we retrieved are often noisy, lack of annotations, or missing some annotations that the model want. As a result, we usually have to spend tremendous amount of time to clean our data and obtain the annotations for our model. This work is one example where the meta-data of dataset do not contain every stylistic properties they want. To solve this, they have to break down movie review into sentences and apply rule-based heuristic to annotate the missing properties for each sentence. For example, to detect if a sentence is descriptive (one of the concerned attribute), they inspect if the sentence has a lot of adjectives. Undoubtedly, such heuristic introduces noise in training data, but they show that such noise does not give significant impact on the model performance.
The authors categorizes two types of stylistic properties they want to control on the dataset.
- properties related to style (e.g. length of the review sentence, whether the review sentence is descriptive)
- properties related to content (e.g. sentiment and theme of the review sentence)
The table below summarizes all the 6 stylistic properties they want to control. Note that the conditional language model could be conditioned on multiple properties at the same time:
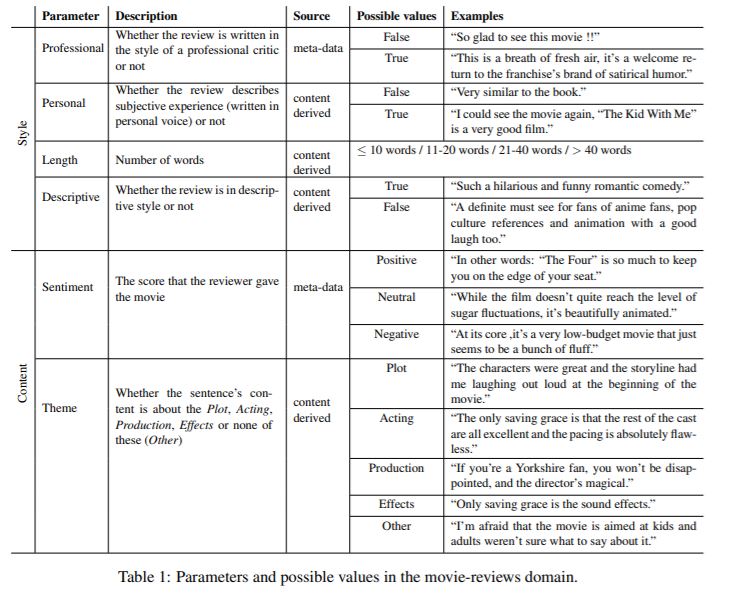
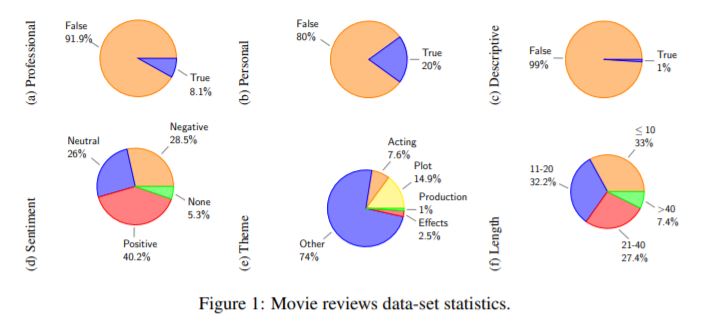
Their final dataset includes 2,773,435 review sentences with each sentence labeled with the 6 stylistic properties. The following chart summarizes the distribution of each stylistic properties:
3. Result
It is tricky to evaluate text generation task. One common metrics is perplexity. It measures how well a language model is fitted to a test set (lower the perplexity the better). The work compares the pexplexity of their conditional language model against unconditional one ans show that it has a better fit than the unconditional one:

Below is a snapshot of the generated reviews conditioned on a set of stylistic properties:

4. Reference
- Ficler, J., & Goldberg, Y. (2017). Controlling Linguistic Style Aspects in Neural Language Generation. In Proc. Workshop on Stylistic Variation, pp. 94–104
- Nitish Shirish Keskar, Bryan McCann, Lav R. Varshney, Caiming Xiong, and Richard Socher. 2019. Ctrl: A conditional transformer language model for controllable generation. ArXiv, abs/1909.05858