[Paper Review] Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures
1. Motivation
Creating an engaging and human-like image caption with machine is a challenging but attractive problem.This paper offers a new angle to approach the problem. It is driven by a critical observation on the modern image captioning models. The authors states the critism towards modern image caption models right straight at the beginning of the abstract:
Recently, deep neural network models have achieved promising results in image captioning task. Yet, “vanilla” sentences, only describing shallow appearances (e.g., types, colors), generated by current works are not satisfied netizen style resulting in lacking engagements, contexts, and user intentions.
The authors further argue such drawback comes from the fact that modern image captioning models usually optimize on metrics used in machine translation, which fails to take into account engagement, humanity and diversity:
Modern methods only focus on optimizing metrics used in machine translation, which causes absence of diversity — producing conservative sentences. These sentences can achieve good scores in machine translation metrics but are short of humanity.
Such monotonic capacity limits the application of image captioning models because they are too inauthentic to draw audience interest. On the contrary, imagine if an image captioning models could generate vivid human-like captions, its potential are tremendous on many areas, such as social media, journalism and advertisement sectors. But then how to teach a model to generate such vivid captions?
2. Contributions
A good human-like caption is engaging, relevant and attractive. As briefly stated above, conventional approach optimizes a model to output a caption of high factual precision for an image. Usually such captions do not sound like human because they solely focus on factual description. A good caption could miss some factual descriptions because user understand a caption together with its image and in some cases image could manifest itself. From a user perspective, a good caption comes into many form: it could be a complement of an image, capturing what is missing in an image; it could also be an emotional expression with respect to the image, sharing what the audience feels about the image. Therefore, a model that could generate vivid image captions should take into account the diversity of its output.
One immediate challenge of this approach is the availability of related dataset. Remember we need high volume of photo-caption pairs to train an image captioning model. Taking COCO dataset as an example, each of its image is augmented with a factual caption in order to train an image captioning model. But using such factual captions as training data are definitely not what they want. To solve this problem, the authors scrape a high volume of posts from a social media platform. Each post is made of an image and comments.
In summary, the paper made the following 3 main contributions with respect to the stated shortcoming of modern image captioning models they stated:
- They collect and release a new large-scale clothing dataset, NetiLook, with 300k posts (photos), and 5 millions comments. Such dataset are rich in human-like and vidid sentences with image-comments pairs (one-to-many relationship).
- They propose to plug in a standalone topic modelling module on top of an image captioning model in order to overcome the lack of diversity of a generated caption.
- They propose three new metrics to measure the diversity of a generated caption
Due to limited length of this post, this post will mainly elaborate the first two contributions of the paper. For details of how they formulate metrics to measure diversity of a generated caption, you could refer to the original paper attached in the reference session of this post.
One caveat about the paper is that it aims to build a vivid human-like image commenting model. Though it is slightly deviate from image captioning, but I believe its approach could also be applied on generating vivid human-like image captions as well. Partly it is a matter of what data we feed to the model.
2. Dataset
NetiLook dataset is scraped from Lookbook, a notable online social platform for clothing style. The community has a huge base of members sharing their personal clothing style and drawing fashion inspiration from each other. A community with such a rich user interaction offers a big potential for an intelligent agent to learn human-like vivid comments with respect to a post (photo).
Besides NetiLook dataset, the authors also use Flickr30k for experiments. Below is an example of these 2 datasets. Notice NetiLook dataset has more diverse and realistic sentences. It shows the relative value of NetiLook dataset in image captioning task.

The presence of social media platform offers a tremendous opportunity for abundance of training data, but they are also too noisy to used out-of-box. The authors have made the following pre-processing steps to clean the data:
- remove images of no comments
- filter sentences that are too long to reduce advertisement and make them more readable
- remove sentences that contain a word frequency that is less than five times in training set
3. Problem Formulation
The framework they proposed is pretty simple to understand and straight-forward to implement. Essentially, the framework starts with training a generic image captioning network with no change in the training phase. To enable the image captioning network to generate human-like vivid comments, they simply train the network with NetiLook or Flickr30k dataset. However, the generated comments/ captions with such trained network is monotonic and lack of diversity.
To introduce diversity of the generated sentences, they introduce an additional standalone module that fused with model output in inference stage to give an adjusted distribution of words. A sentence is then generated with respect to the adjusted distribution of words. The module is able to estimate the latent topics distribution of a post based on its comments (we will explain the part about latent topics later) and output a distribution of words best fit for the mixture of topics (the paper notates the distribution as “style weight”). This distribution controls the network to output diverse comments with respect to an image and its related latent topics. The picture below summarizes an overview of the framework:
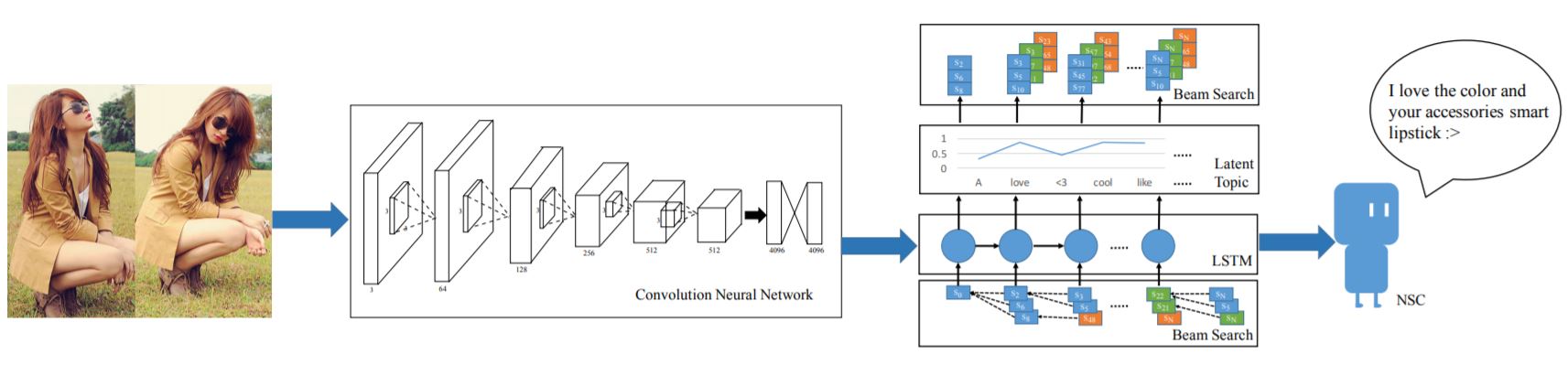
More formally, the comments are generated by beam search according to the final distribution of words in different timestep, $p_{t+1}$:
\[p_{t+1} = Softmax(LSTM(x_{t})) \circ w_{style}, \ t \in 0, ..,. T-1 \\ \\{}\\ x_{t} = W_{e}s_{t}, \ t \geq 0 \\ x_{-1} = CNN(I)\]3.1 What Does the above Formula Mean?
The model for comment generation is essentially a LSTM recurrent network. At the beginning step of the generation, an image $I$ is fed to a pretrained CNN network $CNN(.)$ to obtain a vector of semantic visual features $x_{-1}$. The visual features is then fed to the LSTM network to obtain the first generated word.
The generated word is fed into the LSTM network again to generate the next word, so on and so forth. Before feeding into the LSTM model, the generated word is firstly represented as an one-hot vector $s_{t}$ and then transformed into a semantic feature vector $x_t$ by a word embedding matrix (either pretrained or need to be trained).
$w_{style}$ is the “style weight” from LDA model and $w_{style}$ undergoes a element-wise multiplication with LSTM’s output (after software activation) to give the final distribution of words. With such distribution, we could fall back to typical algorithm such as beam search to generate comments of highest (local) likelihood.
How do we get $w_{style}$ exactly? By a Latent Dirichlet Allocation (LDA) model! The next session wil briefly describe LDA model and how $w_{style}$ is obtained from it.
3.2. Capturing Diversity with Latent Dirichlet Allocation
$w_{style}$ is a distribution of words and such distribution is estimated by a model called Latent Dirichlet Allocation. It is a traditional machine learning model for unsupervised clustering and corpus generation.
LDA framework models the generative process of a corpus and the generative process can best be summarized by the following diagram (borrowed from a slide):

LDA assumes a corpus is made of a fixed number of latent topics, aka ${z_i}^{K}_{i=1}$. We call it latent because those topics may or may not be interpretable. Those latent topics may not even be observable. It further assumes a document is characterized by a distribution of latent topics (e.g. document A is 70% of sports sector and 30% of food sector), and a topic is characterized by a distribution of words (e.g. sports topic has high occurence of “performance”).
To generate a document, LDA firstly assigns a distribution of latent topics for a document, aka $\theta_{D} = {P(z_{1} \mid D), P(z_{2} \mid D), …, P(z_{K} \mid D)}$ where $K$ is the number of latent topics. The distribution can be either assigned by a user or estimated based on the characteristic of the document. With the latent topic distribution $\theta_{D}$, a topic is sampled for each (unobserved) word of the document. With a topic assigned to the (unobserved) word, we have a distribution of words conditional on the topic, aka $\phi_{z} = { P(w_{1} \mid z), P(w_{2} \mid z), …, P(w_N \mid z) }$ where $N$ is the size of vocabulary. Finally, we can sample a (observed) word from the distribution.
In training, LDA model is trying to learn $\theta_{D}$ and $\phi_{Z}$. In inference, it characterize the comments of a post by a latent topic distribution $\theta_{D}$ and computes the style weight $w_{style}$ for its generated comment of the post:
\[w^{j}_{style} = \sum^{K}_{k=1} {\theta^{k}_{D} \phi^{j}_{k}}, \text{ for the j-th word of the comment D}\]Due to limited length, I can’t dive too deep on LDA model. There are many blogposts and videos explaining LDA. For details, you could refer to the resources I attached in the reference session.
4. Results
Results presented by the work is encouraging:

The generated comments in last row are the results of their proposed framework. $NC$ and $Attention$ are the image captioning networks they consider. $NSC_{NC}$ are $NC$ model fused with style weight in post-processing stage.
Undoubtedly, the results are not perfect. Even though they give comments of higher diversity, you could notice it observes a certain pattern here. For example, most of generated comments start with “I love”. It probably reflects a dominant pattern shown in training data.
To demonstrate the generated comments by the proposed framework is more preferable by human. They ask users to rank a human-made comment and the generated comments from $NC$, $Attention$ and $NSC_{NC}$ when given an image. User can assign rank 1-4 to a sentence. Below is a ranking statistics of the user study. The proposed received a high rate of rank 1 assignment. It looks encouraging!

5. Final Thought
In terms of the technicality, the paper does not mention a lot of details about how they train their image captioning network and how they do prediction with their LGDA model. For example, it is not clear on the loss function of the network. They also do not mention how the training handles the case when an image is mapped to multiple comments, which is typically not the setting of current image captioning task. As for LDA, it does not cover how a LDA model infer the per-comment topic distribution for a comment and how it learns the dirichlet distribution for topics. There may be a common practices to follow. I need a deeper look on it.
In terms of the model they proposed, the “vanilla” network learns vivid and human-like sentences from realistic dataset (such as NetiLook) and it achieves diversity by controlling the latent parameters of its standalone LDA module. Such integration is both creative and surprising. I feel really surprised the module is simply plugged on top of an image captioning network but it gives such an impressive results. Notice the LDA module is separately learned from the network. The work serves as a good example of how traditional machine learning framework could work together with deep learning network.
One more insight this paper offers is that we could control text generation by simply manipulating the distribution of word in post-processing stage. Usually we want to treat the attributes we want to control as something learnable in the network, as a result we would put those factor/ data as model input. This paper offers us a much simpler approach for doing this. Instead of taking style weight as a learnable parameters inside the network, this work simply manipulates the distribution of word by style weight which is learned by a LDA model. I believe the idea can be further extended to ways other than LDA, a simpler way such as a manual weighing scheme to penalise or encourage certain words, and more complex way such as a weight that depends on both latent topics and timestep. I look forward to the further works related to this paper.
6. Reference
- Wen Hua Lin, Kuan-Ting Chen, Hung Yueh Chiang, and Winston Hsu. Netizen-Style Commenting on Fashion Photos: Dataset and Diversity Measures. In arXiv preprint, 2018.
- Oriol Vinyals, Alexander Toshev, Samy Bengio, and Dumitru Erhan. 2015. Show and tell: A neural image caption generator. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 3156–3164.
- Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron C Courville, Ruslan Salakhutdinov, Richard S Zemel, and Yoshua Bengio. 2015. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.. In ICML, Vol. 14. 77–81.
- [Youtube] Topic Models: Introduction (13a)
- [Medium] Intuitive Guide to Latent Dirichlet Allocation
- Topic Modeling with Gensim (Python)
- Maximum Likelihood Estimation of Dirichlet Distribution Parameters